Chapter 14: Other recipes
Other recipes
Upgrading
In the "site" page of the administrative interface there is an "upgrade now" button. In case this is not feasible or does not work (for example because of a file locking issue), upgrading web2py manually is very easy.
Simply unzip the latest version of web2py over the old installation.
This will upgrade all the libraries as well as the applications admin, examples, welcome. It will also create a new empty file "NEWINSTALL". Upon restarting, web2py will delete the empty file and package the welcome app into "welcome.w2p" that will be used as the new scaffolding app.
web2py does not upgrade any file in your applications. Some important parts of the framework are not part of the libraries, but part of the Welcome app. New apps will inherit these framework changes, but not existing apps. You need to do copy or merge changes manually. Sometimes this is necessary to take advantage of new functionality, and sometimes it is necessary for compatibility with new releases, particularly if you are using experimental features. The web2py group at Google Groups is a good way to keep track of necessary changes. Parts of the welcome app to copy to existing apps are the appadmin controller, the top-level views including appadmin.html and the generic views, and the contents of the static folder which contains the latest version of important javascript files. Obviously you need to merge your changes (if any). Keeping backups or using a version control system is a sound idea.
# When you upgrade web2py your should update app files that are important to web2py for properly functioning
#
# views/
# appadmin.html
# generic.ics
# generic.load
# generic.rss
# layout.html
# generic.json
# generic.map
# generic.xml
# web2py_ajax.html
# generic.html
# generic.jsonp
# generic.pdf
#
# controller/
# appadmin.py
#
# static/
# css/*
# images/*
# js/*
#
# You can do it with the following bash commands :
# NOTE: Please make a backup of your app before to make sure you don't break anything
#
# From web2py/applications/
cp -R welcome/static/* YOURAPP/static/
cp welcome/controllers/appadmin.py YOURAPP/controllers/
cp -R welcome/views/* YOURAPP/views/
How to distribute your applications as binaries
It is possible to bundle your app with the web2py binary distribution and distribute them together. The license allows this as long you make clear in the license of your app that you are bundling with web2py and add a link to the web2py.com.
Here we explain how to do it for Windows:
- Create your app as usual
- Using admin, bytecode compile your app (one click)
- Using admin, pack your app compiled (another click)
- Create a folder "myapp"
- Download a web2py windows binary distribution
- Unzip it in folder "myapp" and start it (two clicks)
- Upload using admin the previously packed and compiled app with the name "init" (one click)
- Create a file "myapp/start.bat" that contains "web2py/web2py.exe"
- Create a file "myapp/license" that contains a license for your app and make sure it states that it is being "distributed with an unmodified copy of web2py from web2py.com"
- Zip the myapp folder into a file "myapp.zip"
- Distribute and/or sell "myapp.zip"
When users will unzip "myapp.zip" and click "run" they will see your app instead of the "welcome" app. There is no requirement on the user side, not even Python pre-installed.
For Mac binaries the process is the same but there is no need for the "bat" file.
Developing with IDEs: WingIDE, Rad2Py, Eclipse and PyCharm
You can use web2py with third party IDEs such as WingIDE, Rad2Py, Eclipse and PyCharm.
PyCharm
PyCharm v3 Professional Edition introduces built-in support for web2py.
As of v3.0, PyCharm will recognise web2py applications belong to a web2py parent directory, and this will activate the web2py support. Support means that the web2py library is added to the project.
Start a PyCharm project by opening the directory of the web2py installation, and then navigate through the applications directory.
PyCharm's git integration copes with this; it supports multiple git repositories inside the one project directory structure. Keep each application in its own git repository for easy deployment.
The Professional edition includes a default launcher for a web2py project starts web2py.py and therefore launches the integrated rocket server.
PyCharm Debugging tips
You can drop into PyCharm's debugger like any other Python session. This means that you can start debugging the script web2py.py, which will run the rocket server, with PyCharm connected to this process. Use your browser to activate the controller function you are interested it.
When a breakpoint is encountered during the request, you will arrive in PyCharm's debugger.
However, this requires removal of from gluon.debug import dbg statements.
Pycharm: Debugging a module in web2py's context
It can be convenient to directly debug a module with test code in isolation from the rest of web2py. You can make a standard PyCharm run/debug configuration to run a module file as a stand-alone python script and put your testing code in
if __name__ == "__main__":
but then you don't get web2py's models and database connections.
You can make dummy controllers and breakpoint into your module after running the dummy controller function via your browser, as described above, but there is a more convenient option:
Imagine you have this testing block in a module module_1.py:
if __name__ == "__main__":
... code which tests things
and at the same time, you want the database connections and models to be available the same as web2py does normally.
Using web2py command line options, you can make a PyCharm run/debug configuration do this. Make the script: web2py.py Make the script parameters: -S <your_app_name> -M -R /path/to/your_module/module_1.py`:code
This will run the web2py models, and then load your module, which will then run the __main__ code in a context similar to a running web2py app. These command line options are documented in chapter 4.
WingIDE
Here is a screenshot of using web2py with WingIDE:
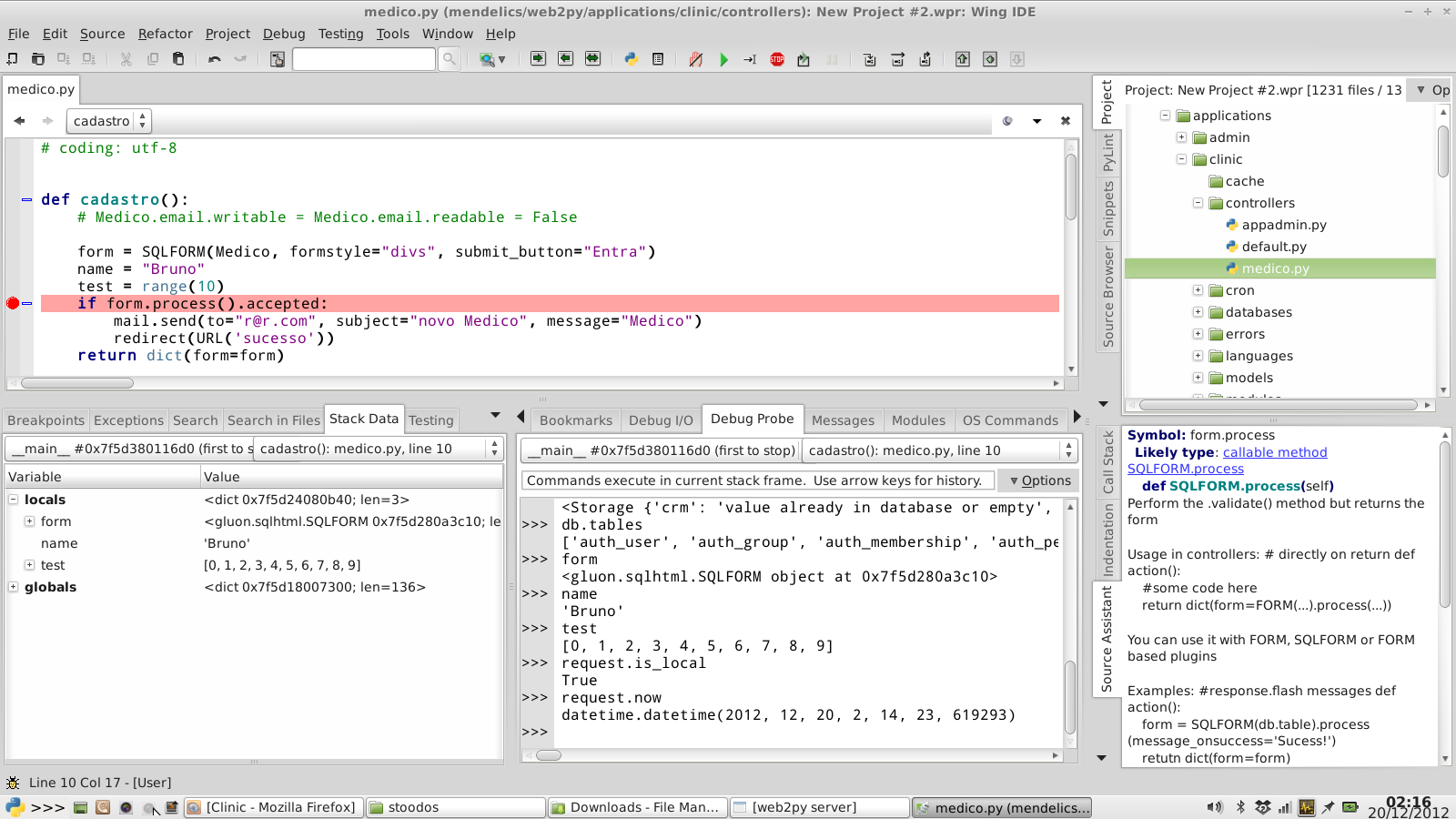
Using general purpose IDEs with web2py
The general problem with these IDEs (except those which support web2py) is that they do not understand the context in which models and controllers are executed and therefore autocompletion does not work out of the box.
To make autocompletion work the general trick consists in editing your models and controllers and adding the following code:
if False:
from gluon import *
request = current.request
response = current.response
session = current.session
cache = current.cache
T = current.T
The import block does not change the logic as this is never executed but it forces the IDE to parse it and understand where the objects in the global namespace come from (the gluon module) thus making autocompletion work.
If you are relying on variables in your models (such as database definitions) you may consider adding to the list like this:
from db import *
You can also consider importing all models.
if False:
from gluon import *
from db import * #repeat for all models
from menu import *
As well, if using Eclipse with PyDev you should add the web2py folder to the system python path (in PyDev preferences for the python interpreter). In some versions of PyDev, it has been possible to use the debugging support inside Eclipse by launching web2py.py. It is probably wise to remove the import of the gluon debug module. Also, to do this you should make the pydev project the web2py directory, not your specific application.
PyDev's git integration copes with this; it supports multiple git repositories inside the one project directory structure.
SQLDesigner
There is a software called SQLDesigner which allows you to build web2py models visually and then generate the corresponding code. Here is a screenshot.
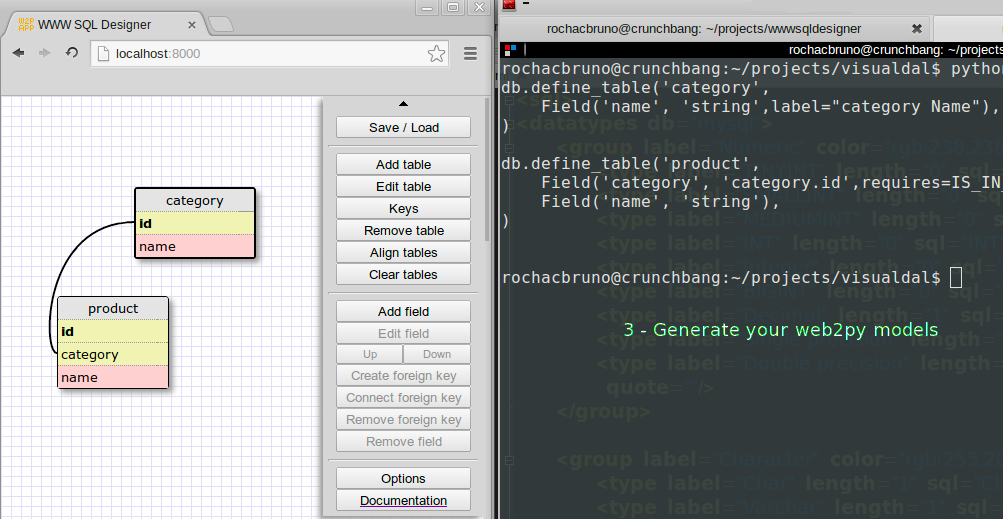
The version of SQLDesigner which works with web2py can be found here:
https://github.com/elcio/visualdalPublishing a folder
Consider the problem of sharing a folder (and subfolders) on the web. web2py makes this very easy. You just need a controller like this:
from gluon.tools import Expose
def myfolder():
return dict(files=Expose('/path/to/myfolder'))
which you can render in a view with {{=files}}. It will create an interface to view the files and folders, and navigate the tree structure. Images will have a preview.
The path prefix "/path/to/myfolder" will be hidden to the visitors. For example a file called "/path/to/myfolder/a/b.txt" will be replaced with "base/a/b.txt". The "base" prefix can be specified using the basename argument of the Expose function. Using the argument extensions can specify a list of file extensions to be listed, other files will be hidden. For example:
def myfolder():
return dict(files=Expose('/path/to/myfolder', basename='.',
extensions=['.py', '.jpg']))
Files and folders that contain the word "private" in the path or have file that start with "." or terminate in "~" are always hidden.
Functional testing
web2py comes with a module gluon.contrib.webclient which allows functional testing of local and remote web2py applications. Actually, this module is not web2py specific and it can be used for testing and interacting programmatically with any web application, yet it is designed to understand web2py session and web2py postbacks.
Here is an example of usage. The program below creates a client, connects to the "index" action in order to establish a session, registers a new user, then logouts, and logins again using the newly created credentials:
from gluon.contrib.webclient import WebClient
client = WebClient('http://127.0.0.1:8000/welcome/default/',
postbacks=True)
client.get('index')
# register
data = dict(first_name='Homer',
last_name='Simpson',
email='homer@web2py.com',
password='test',
password_two='test',
_formname='register')
client.post('user/register', data=data)
# logout
client.get('user/logout')
# login again
data = dict(email='homer@web2py.com',
password='test',
_formname='login')
client.post('user/login', data=data)
# check registration and login were successful
client.get('index')
assert('Welcome Homer' in client.text)
The WebClient constructor takes a URL prefix as argument. In the example that is "http://127.0.0.1:8000/welcome/default/". It does not perform any network IO. The postbacks argument defaults to True and tells the client how to handle web2py postbacks.
The WebClient object, client, has only two methods: get and post. The first argument is always a URL postfix. The full URL for the GET of POST request is constructed simply by concatenating the prefix and the postfix. The purpose of this is imply making the syntax less verbose for long conversations between client and server.
data is a parameter specific of POST request and contains a dictionary of the data to be posted. Web2py forms have a hidden _formname field and its value must be provided unless there is a single form in the page. Web2py forms also contain a hidden _formkey field which is designed to prevent CSRF attacked. It is handled automatically by WebClient.
Both client.get and client.post accept the following extra arguments:
headers: a dictionary of optional HTTP headers.cookies: a dictionary of optional HTTP cookies.auth: a dictionary of parameters to be passed tourllib2.HTTPBasicAuthHandler().add_password(**auth)in order to perform basic authentication. For more information about this we refer to the Python documentation for the urllib2 module.
The client object in the example carries on a conversation with the server specified in the constructor by making GET and POST requests. It automatically handles all cookies and sends them back to maintain sessions. If it detects that a new session cookie is issued while an existing one is already present, it interprets it as a broken session and raises an exception. If the server returns an HTTP error, it raises an exception. If the server returns an HTTP error which contains a web2py ticket, it returns a RuntimeError exception containing the ticket code.
The client object maintains a log of requests in client.history and a state associated with its last successful request. The state consists of:
client.status: the returned status codeclient.text: the content of the pageclient.headers: a dictionary of parsed headersclient.cookies: a dictionary of parsed cookiesclient.sessions: a dictionary of web2py sessions in the form{appname: session_id}.client.forms: a dictionary of web2py forms detected in theclient.text. The dictionary has the form{_formname, _formkey}.
The WebClient object does not perform any parsing of the client.text returned by the server but this can easily be accomplished with many third-party modules such as BeautifulSoup. For example here is an example code that finds all links in a page downloaded by the client and checks all of them:
from BeautifulSoup import BeautifulSoup
dom = BeautifulSoup(client.text)
for link in dom.findAll('a'):
new_client = WebClient()
new_client.get(a.href)
print new_client.statusBuilding a minimalist web2py
Some times we need to deploy web2py in a server with very small memory footprint. In this case we want to strip down web2py to its bare minimum.
An easy way to do it is the following:
- On a production machine, install the full web2py from source
- From inside the main web2py folder run
python scripts/make_min_web2py.py /path/to/minweb2py- Now copy under "/path/to/minweb2py/applications" the applications you want to deploy
- Deploy "/path/to/minweb2py" to the small footprint server
The script "make_min_web2py.py" builds a minimalist web2py distribution that does not include:
- admin
- examples
- welcome
- scripts
- rarely used contrib modules
It does include a "welcome" app consisting of a single file to allow testing deployment. Look into this script. At the top it contains a detailed list of what is included and what is ignored. You can easily modify it and tailor to your needs.
Fetching an external URL
Python includes the urllib library for fetching urls:
import urllib
page = urllib.urlopen('http://www.web2py.com').read()
This is often fine, but the urllib module does not work on the Google App Engine. Google provides a different API for downloading URLs that works on GAE only. In order to make your code portable, web2py includes a fetch function that works on GAE as well as other Python installations:
from gluon.tools import fetch
page = fetch('http://www.web2py.com')
Pretty dates
It is often useful to represent a datetime not as "2009-07-25 14:34:56" but as "one year ago". web2py provides a utility function for this:
import datetime
d = datetime.datetime(2009, 7, 25, 14, 34, 56)
from gluon.tools import prettydate
pretty_d = prettydate(d, T)
The second argument (T) must be passed to allow internationalization for the output.
Geocoding
If you need to convert an address (for example: "243 S Wabash Ave, Chicago, IL, USA") into geographical coordinates (latitude and longitude), web2py provides a function to do so.
from gluon.tools import geocode
address = '243 S Wabash Ave, Chicago, IL, USA'
(latitude, longitude) = geocode(address)
The function geocode requires a network connection and it connects to the Google geocoding service for the geocoding. The function returns (0,0) in case of failure. Notice that the Google geocoding service caps the number of requests, so you should check their service agreement. The geocode function is built on top of the fetch function and thus it works on GAE.
Pagination
This recipe is a useful trick to minimize database access in case of pagination, e.g., when you need to display a list of rows from a database but you want to distribute the rows over multiple pages.
Start by creating a primes application that stores the first 1000 prime numbers in a database.
Here is the model db.py:
db = DAL('sqlite://primes.db')
db.define_table('prime', Field('value', 'integer'))
def isprime(p):
for i in range(2, p):
if p%i==0: return False
return True
if len(db().select(db.prime.id))==0:
p=2
for i in range(1000):
while not isprime(p): p+=1
db.prime.insert(value=p)
p+=1
Now create an action list_items in the "default.py" controller that reads like this:
def list_items():
if len(request.args): page=int(request.args[0])
else: page=0
items_per_page=20
limitby=(page*items_per_page, (page+1)*items_per_page+1)
rows=db().select(db.prime.ALL, limitby=limitby)
return dict(rows=rows, page=page, items_per_page=items_per_page)
Notice that this code selects one more item than is needed, 20+1. The extra element tells the view whether there is a next page.
Here is the "default/list_items.html" view:
{{extend 'layout.html'}}
{{for i, row in enumerate(rows):}}
{{if i==items_per_page: break}}
{{=row.value}}<br />
{{pass}}
{{if page:}}
<a href="{{=URL(args=[page-1])}}">previous</a>
{{pass}}
{{if len(rows)>items_per_page:}}
<a href="{{=URL(args=[page+1])}}">next</a>
{{pass}}
In this way we have obtained pagination with one single select per action, and that one select only selects one row more than we need.
httpserver.log and the Log File Format
The web2py web server logs all requests to a file called:
httpserver.log
in the root web2py directory. An alternative filename and location can be specified via web2py command-line options.
New entries are appended to the end of the file each time a request is made. Each line looks like this:
127.0.0.1, 2008-01-12 10:41:20, GET, /admin/default/site, HTTP/1.1, 200, 0.270000
The format is:
ip, timestamp, method, path, protocol, status, time_taken
Where
- ip is the IP address of the client who made the request
- timestamp is the date and time of the request in ISO 8601 format, YYYY-MM-DDT HH:MM:SS
- method is either GET or POST
- path is the path requested by the client
- protocol is the HTTP protocol used to send to the client, usually HTTP/1.1
- status is the one of the HTTP status codes [status]
- time_taken is the amount of time the server took to process the request, in seconds, not including upload/download time.
In the appliances repository [appliances] , you will find an appliance for log analysis.
This logging is disabled by default when using mod_wsgi since it would be the same as the Apache log.
Populating database with dummy data
For testing purposes, it is convenient to be able to populate database tables with dummy data. web2py includes a Bayesian classifier already trained to generate dummy but readable text for this purpose.
Here is the simplest way to use it:
from gluon.contrib.populate import populate
populate(db.mytable, 100)
It will insert 100 dummy records into db.mytable. It will try to do intelligently by generating short text for string fields, longer text for text fields, integers, doubles, dates, datetimes, times, booleans, etc. for the corresponding fields. It will try to respect requirements imposed by validators. For fields containing the word "name" it will try to generate dummy names. For reference fields it will generate valid references.
If you have two tables (A and B) where B references A, make sure to populate A first and B second.
Because population is done in a transaction, do not attempt to populate too many records at once, particularly if references are involved. Instead, populate 100 at a time, commit, loop.
for i in range(10):
populate(db.mytable, 100)
db.commit()
You can use the Bayesian classifier to learn some text and generate dummy text that sounds similar but should not make sense:
from gluon.contrib.populate import Learner, IUP
ell=Learner()
ell.learn('some very long input text ...')
print ell.generate(1000, prefix=None)
Accepting credit card payments
There are multiple ways to accept credit card payments online. web2py provides specific APIs for some of the most popular and practical ones:
- Google Wallet [googlewallet]
- PayPal [paypal]
- Stripe.com [stripe]
- Authorize.net [authorizenet]
- DowCommerece [dowcommerce]
The first two mechanisms above delegate the process of authenticating the payee to an external service. While this is the best solution for security (your app does not handle any credit card information at all) it makes the process cumbersome (the user must login twice; for example, once with your app, and once with Google) and does not allow your app to handle recurrent payments in an automated way.
There are times when you need more control and you want to generate yourself the entry form for the credit card info and than programmatically ask the processor to transfer money from the credit card to your account.
For this reason web2py provide integration out of the box with Stripe, Authorize.net (the module was developed by John Conde and slightly modified) and DowCommerce. Stripe is the simplest to use and also the cheapest for low volume of transactions (they charge no fix cost but charge about 3% per transaction). Authorize.net is better for high volumes (has a fixed yearly costs plus a lower cost per transaction).
Mind that in the case of Stripe and Authorize.net your program will be accepting credit cards information. You do not have to store this information and we advise you not to because of the legal requirements involved (check with Visa or MasterCard), but there are times when you may want to store the information for recurrent payments or to reproduce the Amazon one-click pay button.
Google Wallet
The simplest way to use Google Wallet (Level 1) consists of embedding a button on your page that, when clicked, redirects your visitor to a payment page provided by Google.
First of all you need to register a Google Merchant Account at the url:
https://checkout.google.com/sellYou will need to provide Google with your bank information. Google will assign you a merchant_id and a merchant_key (do not confuse them, keep them secret).
Then you simply need to create the following code in your view:
{{from gluon.contrib.google_wallet import button}}
{{=button(merchant_id="123456789012345",
products=[dict(name="shoes",
quantity=1,
price=23.5,
currency='USD',
description="running shoes black")])}}When a visitor clicks on the button, the visitor will be redirected to the Google page where he/she can pay for the items. Here products is a list of products and each product is a dictionary of parameters that you want to pass describing your items (name, quantity, price, currency, description, and other optional ones which you can find described in the Google Wallet documentation).
If you choose to use this mechanism, you may want to generate the values passed to the button programmatically based on your inventory and the visitor shopping chart.
All the tax and shipping information will be handled on the Google side. Same for accounting information. By default your application is not notified that the transaction has been completed therefore you will have to visit your Google Merchant site to see which products have been purchased and paid for, and which products you need to ship to your buyers there. Google will also send you an email with the information.
If you want a tighter integration, you have to use the Level 2 notification API. In that case you can pass more information to Google and Google will call your API to notify about purchases. This allows you to keep accounting information within your application but it requires you expose web services that can talk to Google Wallet.
This is a considerable more difficult problem but such API has already been implemented and it is available as plugin from
http://web2py.com/plugins/static/web2py.plugin.google_checkout.w2pYou can find the documentation of the plugin in the plugin itself.
Paypal
Paypal integration is not described here but you can find more information about it at this resource:
http://www.web2pyslices.com/main/slices/take_slice/9Stripe.com
This is probably one of the easiest way and flexible ways to accept credit card payments.
You need to register with Stripe.com and that is a very easy process, in fact Stripe will assign you an API key to try even before you create any credentials.
Once you have the API key you can accept credit cards with the following code:
from gluon.contrib.stripe import Stripe
stripe = Stripe(api_key)
d = stripe.charge(amount=100,
currency='usd',
card_number='4242424242424242',
card_exp_month='5',
card_exp_year='2012',
card_cvc_check='123',
description='the usual black shoes')
if d.get('paid', False):
# payment accepted
elif:
# error is in d.get('error', 'unknown')The response, d, is a dictionary which you can explore yourself. The card number used in the example is a sandbox and it will always succeed. Each transaction is associated to a transaction id stored in d['id'].
Stripe also allows you to verify a transaction at a later time:
d = Stripe(key).check(d['id'])and refund a transaction:
r = Stripe(key).refund(d['id'])
if r.get('refunded', False):
# refund was successful
elif:
# error is in d.get('error', 'unknown')Stripe makes very easy to keep the accounting within your application.
All the communications between your app and Stripe go over RESTful web services. Stripe actually exposes even more services and provides a larger set of Python API. You can read more on their web site.
Authorize.Net
Another simple way to accept credit cards is to use Authorize.Net. As usual you need to register and you will obtain a login and a transaction key (transkey. Once you have them it works very much like Stripe does:
from gluon.contrib.AuthorizeNet import process
if process(creditcard='4427802641004797',
expiration="122012",
total=100.0, cvv='123', tax=None, invoice=None,
login='cnpdev4289', transkey='SR2P8g4jdEn7vFLQ', testmode=True):
# payment was processed
else:
# payment was rejected
If you have a valid Authorize.Net account you should replace the sandbox login and transkey with those of your account, set testmode=False to run on the real platform instead of the sandbox, and use credit card information provided by the visitor.
If process returns True, the money has been transferred from the visitor credit card account to your Authorize.Net account. invoice is just a string that you can set and will be store by Authorize.Net with this transaction so that you can reconcile the data with the information in your application.
Here is a more complex example of workflow where more variables are exposed:
from gluon.contrib.AuthorizeNet import AIM
payment = AIM(login='cnpdev4289',
transkey='SR2P8g4jdEn7vFLQ',
testmod=True)
payment.setTransaction(creditcard, expiration, total, cvv, tax, invoice)
payment.setParameter('x_duplicate_window', 180) # three minutes duplicate windows
payment.setParameter('x_cust_id', '1324') # customer ID
payment.setParameter('x_first_name', 'Agent')
payment.setParameter('x_last_name', 'Smith')
payment.setParameter('x_company', 'Test Company')
payment.setParameter('x_address', '1234 Main Street')
payment.setParameter('x_city', 'Townsville')
payment.setParameter('x_state', 'NJ')
payment.setParameter('x_zip', '12345')
payment.setParameter('x_country', 'US')
payment.setParameter('x_phone', '800-555-1234')
payment.setParameter('x_description', 'Test Transaction')
payment.setParameter('x_customer_ip', socket.gethostbyname(socket.gethostname()))
payment.setParameter('x_email', 'you@example.com')
payment.setParameter('x_email_customer', False)
payment.process()
if payment.isApproved():
print 'Response Code: ', payment.response.ResponseCode
print 'Response Text: ', payment.response.ResponseText
print 'Response: ', payment.getResultResponseFull()
print 'Transaction ID: ', payment.response.TransactionID
print 'CVV Result: ', payment.response.CVVResponse
print 'Approval Code: ', payment.response.AuthCode
print 'AVS Result: ', payment.response.AVSResponse
elif payment.isDeclined():
print 'Your credit card was declined by your bank'
elif payment.isError():
print 'It did not work'
print 'approved', payment.isApproved()
print 'declined', payment.isDeclined()
print 'error', payment.isError()
Notice the code above uses a dummy test account. You need to register with Authorize.Net (it is not a free service) and provide your own login, transkey, testmode=True or False to the AIM constructor.
Dropbox API
Dropbox is a very popular storage service. It not only stores your files but it keeps the cloud storage in sync with all your machines. It allows you to create groups and give read/write permissions to the various folders to individual users or groups. It also keeps version history of all your files. It includes a folder called "Public" and each file you put in there will have its own public URL. Dropbox is a great way to collaborate.
You can access dropbox easily by registering at
https://www.dropbox.com/developersyou will get an APP_KEY and an APP_SECRET. Once you have them you can use Dropbox to authenticate your users.
Create a file called "yourapp/private/dropbox.key" and in it write
<APP_KEY>:<APP_SECRET>:app_folderwhere <APP_KEY> and <APP_SECRET> are your key and secret. The third part could be app_folder or dropbox or auto.
Install the dropbox sdk from "https://www.dropbox.com/developers/core/sdks/python".
Then in "models/db.py" do:
from gluon.contrib.login_methods.dropbox_account import use_dropbox
use_dropbox(auth, filename='private/dropbox.key')
mydropbox = auth.settings.login_formThis will allow users to login into your app using their dropbox credentials, and your program will be able to upload files into their dropbox account:
stream = open('localfile.txt', 'rb')
mydropbox.put('destfile.txt', stream)download files:
stream = mydropbox.get('destfile.txt')
open('localfile.txt', 'wb').write(read)and get directory listings:
contents = mydropbox.dir(path = '/')['contents']Streaming virtual files
It is common for malicious attackers to scan web sites for vulnerabilities. They use security scanners like Nessus to explore the target web sites for scripts that are known to have vulnerabilities. An analysis of web server logs from a scanned machine or directly in the Nessus database reveals that most of the known vulnerabilities are in PHP scripts and ASP scripts. Since we are running web2py, we do not have those vulnerabilities, but we will still be scanned for them. This is annoying, so we like to respond to those vulnerability scans and make the attacker understand their time is being wasted.
One possibility is to redirect all requests for .php, .asp, and anything suspicious to a dummy action that will respond to the attack by keeping the attacker busy for a large amount of time. Eventually the attacker will give up and will not scan us again.
This recipe requires two parts.
A dedicated application called jammer with a "default.py" controller as follows:
class Jammer():
def read(self, n): return 'x'*n
def jam(): return response.stream(Jammer(), 40000)
When this action is called, it responds with an infinite data stream full of "x"-es. 40000 characters at a time.
The second ingredient is a "route.py" file that redirects any request ending in .php, .asp, etc. (both upper case and lower case) to this controller.
route_in=(
('.*.(php|PHP|asp|ASP|jsp|JSP)', 'jammer/default/jam'),
)
The first time you are attacked you may incur a small overhead, but our experience is that the same attacker will not try twice.